Posted by Sam on Jan 14, 2009 at 12:00 AM UTC - 5 hrs
This is the first in a series of my answers to Jurgen Appelo's list of
100 Interview Questions for Software Developers.
Jurgen is a software development manager and CIO at
ISM eCompany, according to
his About page.
The list is not intended to be a "one-size-fits-all, every developer must know the correct answer to all questions" list.
Instead, Jurgen notes:
The key is to ask challenging questions that enable you to distinguish the smart software developers from the moronic mandrills.
...
This list covers most of the knowledge areas as defined by the Software Engineering Body of Knowledge.
Of course, if you're just looking for brilliant programmers, you may want to limit the topics to [the]
Construction, Algorithms, Data Structures and Testing [sections of the list].
And if you're looking for architects, you can just consider the questions under the headings
Requirements, Functional Design and Technical Design.
But whatever you do, keep this in mind:
For most of the questions in this list there are no right and wrong answers!
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers, as if I had not
prepared for the interview at all. The format will first list the question, my initial response (to start
the discussion), followed by a place I might have looked for further information had I seen the questions
and prepared before answering them.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy.
More...
Requirements
- Can you name a number of non-functional (or quality) requirements?
I'd first mention performance and security, from the user's perspective. I'd then mention meeting minimum
requirements for metrics like code coverage in testing and dependencies in our design. I don't consider
code quality out-of-order when it comes to requirements.
The non-functional requirements
page at Wikipedia lists several examples. Notable exceptions from my quickie-response: accessibility,
documentation, portability. There are several that are listed that I consider covered by what I've listed,
but I missed some that caused me to say

- What is your advice when a customer wants high performance, high usability and high security?
My "advice" starts with the questions: "What do you consider X to be?" where X belongs to the set {"high performance",
"high usability", "high security"}. I might offer that I consider "high performance"
to be a misnomer, as it's either acceptable or not, and that unless the customer defines it, I don't
know how we'd even attempt to measure something as vague as "usability."
I'm not sure where I'd prepare for this question. Any suggestions are appreciated.
- Can you name a number of different techniques for specifying requirements? What works best in which case?
I can name several: tell me in person, tell me over email, tell me over IM or
over the phone.
I know that's not what you're looking for. You're looking for answers like "use cases." It all boils down to the same.
I might even mention "unit tests" here. That's part of the spec, as far as I'm concerned, and for almost
any software I write for myself, it's the only way I specify requirements (except for maybe a very informal to-do
list).
Face-to-face works best in most cases, I'd gather.
The answer after doing some research: ¡Ay, ay, ay, no me gusta! I didn't see this coming. There are a number of things that could qualify as answers
(Prototyping, Storyboards, Modeling, ..., State transitions) that I knew about beforehand. I thought to include
none of them.

- What is requirements tracing? What is backward tracing vs. forward tracing?
My response? "I don't know anything about requirements tracing. I'm willing to learn."
Once again, Wikipedia tells us about requirements
traceability, illuminating the issue for us.
- Which tools do you like to use for keeping track of requirements?
I generally use a combination of a text file and emails, as far as the client is concerned. If it's a larger
system, I'll use something like Sharepoint, Basecamp,
or another system that performs a similar function. I have no preferences, because nothing I've ever used
compares to a simple list. If it does, it's equally useful.
I don't know that I'd say I like any of them. In reality I prefer a simple to-do list that I encode in
tests (insofar as I'm capable of writing the tests) and knock them out one-by-one.
- How do you treat changing requirements? Are they good or bad? Why?
I don't give a value judgement on changing requirements: they are inevitable. They can be good or bad depending on
how the client handles them.
I always try to let the client know: I can do X amount in Y timeframe. You asked for Z total.
Here's an estimate for each item in Z, pick X from it for our current Y timeframe. I'll get back to you every Y timeframe to show a demo,
and you can choose X from the remaining Z again (with changes based on circumstances if required). Feel free
to fire me when you have enough out of Z that's functional. (Ok, I probably wouldn't say the last sentence in those
terms, but I'd find a way to say it, if for no other reason than to sell them the rest of the process.)
As far as looking it up before the interview: I've review Agile literature. Searching any of the agile yahoo groups
for the question at hand ought to be good enough.
- How do you search and find requirements? What are possible sources?
"What do you mean?" would be my response. I really don't know. What does searching and finding requirements mean?
Does it mean figuring out how to do requirements that I don't know how to accomplish?
If so, the first step is Google. In
the rare event no one that I can find has had my problem, I'll go traipsing through the source code if
it's available.
Clearly, I don't know where to start here.
- How do you prioritize requirements? Do you know different techniques?
I rarely prioritize requirements. I let the customer decide. I give them a relative cost of implementing
X requirement vs. implementing Y requirement, and let them decide. If Y requires X, then I tell them
so.
I know of different techniques - take "random" for example. I don't know what they might be called. But I
cannot think of anything better, even if it were decreed as a Top 10 Commandment for Prioritizing Requirements.
No web search for this comes to mind. I'd review a couple of process management books if I had no clue.
This seems to be a decent discussion,
if you must have one from me from a cursory browse.
- Can you name the responsibilities of the user, the customer and the developer in the
requirements process?
The user will be the person using the software, versus the customer being the one who pays for its development.
I hate that distinction. The developer programs it. Responsibilities? In my ideal organization, I'd have:
-
Developers working with the Customer to manage requirements.
-
Developers working with the User to make the application work for them regardless of the Customer (I've
seen too many projects where the User had to use whatever the Customer purchased, even
if the purchase was ... little yellow bus-ish.)
-
Customer/User having daily meetings with the developer
-
Developer making the best software he/she can given the constraints.
Again, I don't know where I'd look this up before being asked. Suggestions (again, as always) are most welcome.
- What do you do with requirements that are incomplete or incomprehensible?
I send an email saying "I don't understand what you mean. Please read the very small attached book
and get back to me."

Just kidding, of course (at least in most cases. I've been recently tempted to send that exact email, as it happens.)
I just ask them to clarify. If I don't have contact with the customer, I ask the intermediary to clarify or
get clarification.
Outside reading: Agile, and hopefully other processes for some compare and contrast.
I think these are decent answers to start a discussion with. If you're a hiring manager, what do you say? Would you show me the door, or keep me around for a while longer?
It's not quite as hard as Steve Yegge's list
of things to know (I'll get to that eventually), but it's a good (and more well-rounded!) list nevertheless.
How would you answer the Requirements questions?
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Posted by Sam on Jan 29, 2009 at 12:00 AM UTC - 5 hrs
This is the second in a series of
answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not
prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy.
My lack of understanding the angle from which these questions come may influence other seemingly off-base
answers. Help me out by explaining how you might answer these questions on functional design:
More...
- What are metaphors used for in functional design? Can you name some successful examples?
I hate to start the first one off with an IDK,
but what else can you do? I feel like I can talk intelligently about
some of the issues involved in functional design, but until now, I never realized it was a process unto itself,
nor did I know what all it entailed until after I browsed the remaining questions.
Reading: The Wikipedia page on functional design
is delightfully lacking any useful information about the topic. However, these functional design guidelines
on Smashing Magazine seem to be a reasonable starting point.
- How can you reduce the user's perception of waiting when some functions take a lot of time?
Show a progress bar. Distract them with something they need to read or stage data-collection/interaction with the user.
Of course,
the obvious yet overlooked answer here would be to make the offending functions faster. At
worst, if the function doesn't require user interaction at all, you could spawn a new thread to do the work
in the background and let the user continue working. Then they'd notice no waiting at all.
Reading: I picked this up from observation and deduction. I don't know where I'd go to read such information.

- Which controls would you use when a user must select multiple items from a big list, in a minimal amount of space?
What controls do I have to pick from? Can the list be grouped by some recurring values? For instance, consider
how the iPod uses the scroll wheel to let you navigate a long list of music. Now apply finding one song to
finding several, and you have an idea of what I'm talking about.
Another option might be to have auto-complete, with a special key for "add to list" when you're satisfied, which
puts you back at the beginning of the text box. Another key would end the sequence.
Can you visualize the list in some way? The user could then click pictures to drill down and roll up on items
in the list, viewing it from different levels. For example, if the list was of colors,
you could take the typical color-picker from every image program out there, and use it to choose your list.
Reading: I came up with these on the spot, and can't say I've seen them completely implemented yet,
so again, when it comes time for advice on where to read up on this topic, I've got nothing.
- Can you name different measures to guarantee correctness of data entry?
Aside from the pains of torture? You'll definitely want a fast-acting validation to let the user
know as soon as possible that you think their input is incorrect. When talking about the web, you'll
want to validate it server side as well. You'll want to show some examples if you need a certain format
of input (or just if the customer expects to be forced into a format, you'll want to relieve their anxiety
by providing an example). Finally, make the user type as little as possible, except if you're doing a progressive
lookup / autocomplete on their typing.
Reading list is vacant. Please advise.

- Can you name different techniques for prototyping an application?
At first, I didn't realize there were different techniques. Unless we were talking about storyboards vs.
mark-up-only or a shell of an application. I don't imagine that was the point.
I did find something that I think was the point: for reading, Scott Ambler has a take from a different point of view: tips and techniques
in user interface prototyping that includes another list of resources. A treasure trove!
Now that I know what we're talking about, I'd have given similar answers. I feel I could have been effective
in a conversation about this, but the other party would have had to lead me that direction. I couldn't get
there from the question alone.
- Can you name examples of how an application can anticipate user behavior?
Analyze it and look for patterns. Use a Markov Model to predict next action based on previous N actions.
That's the only way (well, there are variation on the same theme) I can think of that an
application would do it. We could of course observe the users and make changes ourselves. I don't think
that would be a bad idea.
Reading is nonexistent. Those ideas came from elsewhere, but never as part of functional design.
- Can you name different ways of designing access to a large and complex list of features?
There's the outmoded File/Edit/View tree menu controls (find link to discussion), ribbon interfaces,
and
progressive search, or autocomplete.
I'd also consider re-purposing my answers to #3.
- How would you design editing twenty fields for a list of 10 items? And editing 3 fields for a list of 1000 items?
For the latter, I'd almost certainly put them all in one page. Or 100+ at a time. The fewer clicks the better.
It's worth importing from a spreadsheet every time, if that's an option.
For the former- Can the 20 fields be broken down into more cohesive units? Twenty fields in one form is often too many.
10 forms is not absurd, on the other hand.
- What is the problem of using different colors when highlighting pieces of a text?
The highlight color can make the text hard(er) or downright impossible to read. Anything else?
I don't see room for discussion, unless you're flashing the colors -- then you might get into causing
epileptic seizures in those susceptible to them.
- Can you name some limitations of a web environment vs. a Windows environment?
Access to the file system. Lag mainly - less responsive experience for most of web than on Windows.
As you can tell - while some of these questions are ones I've thought about in the past, or touch themes on others
that I do - I haven't thought about functional design as a process by itself.
So in that regard I ask,
Do you have any pointers?
Posted by Sam on Mar 26, 2009 at 12:00 AM UTC - 5 hrs
This is the seventh in a
series of answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
This week's answers are about testing.
More...
- Do you know what a regression test is? How do you verify that new changes have not broken existing features?
You answered the second part of the question with the first: you run regression tests to ensure that
new changes have not broken existing features. For me, regression tests come in the form of already written tests,
especially unit tests that I've let turn into integration tests. However, you could write a regression test
before making a new change, and it would work as well.
The point is that you want to have some tests in place so that when you inevitably make changes, you can ensure
they didn't cascade throughout the system introducing bugs.
- How can you implement unit testing when there are dependencies between a business layer and a data layer?
Generally I'd let that unit test become an integration test. But if the time to run the tests was becoming
too long, I'd build a mock object that represented the data layer without hitting the database or file
system, and that would be expected to decrease the running time significantly.
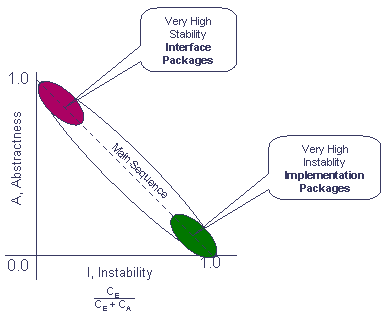
- Which tools are essential to you for testing the quality of your code?
I don't know if anything is essential. If you've got asserts or throws, you
can always implement testing yourself, and a good eye for bad code helps as well. That said, to reduce
psychological barriers
to testing, it would be nice to have tools already made for this purpose.
Luckily, we have such tool available: unit testing frameworks and static code analysis tools in your language of choice.
- What types of problems have you encountered most often in your products after deployment?
Most recently I've encountered very specific integration errors, and written about some ideas on
fixing the polysystemic testing nightmare.
- Do you know what code coverage is? What types of code coverage are there?
Generally I'd thought it refers to the percentage of code covered by tests. I don't know what
the second question here refers to, as I thought it referred exclusively to testing.
- Do you know the difference between functional testing and exploratory testing? How would you test a web site?
I have to admit that before being asked this question, I wouldn't have thought about it. My guess is that
functional testing refers to testing the expected functionality of an application, whereas exploratory
testing involves testing without knowing any specific expectations.
As far as testing a web site, I'll have plenty of unit tests, some acceptance tests, perhaps some in
Selenium or a similar offering, as well as load testing. These aren't specific to web apps, however, except
for load testing in most cases.
I'm very interested in feedback here, given my misunderstanding of the question. If you can offer it, let me
thank you in advance.
- What is the difference between a test suite, a test case and a test plan? How would you organize testing?
A test suite is made up of test cases. I'm not sure what a test plan is, aside from the obvious which the
name would suggest. As far as organizing testing: I tend to organize my unit tests by class, with the method
they test in the same order they exist within that class.
- What kind of tests would you include for a smoke test of an ecommerce web site?
Again, here's another where I didn't know the terminology, so having to ask would result in demerits, but
knowing the answer of "what is a smoke test?" allows us to properly answer the question:
In software testing, a smoke test is a collection of written tests that are performed on a system prior to being accepted for further testing.

In that case, I'd click around (or more likely, write an application that could be run many times that does the same thing,
or use that application to write Selenium tests) looking for problems. I'd fill out some forms, and leave others blank.
Ideally, it would all be random, so as to find problems with the specs as often as possible without actually
testing all the specs, since the point seems to be to give us a quick way to reject the release without
doing full testing.
- What can you do reduce the chance that a customer finds things that he doesn't like during acceptance testing?
The best thing to do is to use incremental and iterative development that keeps the customer in the
loop providing feedback before you get down to acceptance testing. Have effective tests in place that
cover his requirements and ensure you hit those tests. When you come across something you know
won't pass muster, address it even though it might not be a formal requirement.
There are undoubtedly underhanded ways to achieve that goal as well, but I'm not in the habit of going
that direction, so I won't address them here.
- Can you tell me something that you have learned about testing and quality assurance in the last year?
Again I'm going to reference my polysystemic testing nightmare,
because it taught me that testing is extremely hard when you don't have the right tools at your disposal, and that
sometimes, you've got to create them on your own.
As far as reading goes, I'd start with literature on TDD, as it's
the most important yet underused as far as I'm concerned.
What advice would you give?
Posted by Sam on Mar 05, 2009 at 12:00 AM UTC - 5 hrs
This is the fourth in a series of
answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
More...
- How do you make sure that your code can handle different kinds of error situations?
I write tests that describe the expected error situations and check to see that they are handled appropriately.
If the software is legacy and prone to generating exceptions, I'll wrap it up to report the exceptions
to get an idea of what needs attention first, and start attacking it there. Of course where required,
we'll use try/catch.
Mostly I try to follow the rigorous WOMM development process.

- Can you explain what Test-Driven Development is? Can you name some principles of Extreme Programming?
TDD: Red, Green, Refactor. You write a test that specifies some behavior the code should produce. Run the test
to make sure it fails. Write code to make the test pass, then run it to make sure it passes. Change the
code as needed to improve its design.
XP: Aside from testing, we want to continuously review code through pair programming, maintain sustainable
work conditions with sane work-weeks, and continually integrate our code to reduce the time we have to
spend working out kinks in that process. There's more, but those are a few.
Reading: Xprogramming.com is a good starting point.
The associated lists (TDD and XP) on Yahoo Groups are great for discussion. It's probably worth reading
a book or two on the subjects. I'd recommend Kent Beck or Ron Jeffries.
- What do you care about most when reviewing somebody else's code?
Does it say what it's doing, and do it correctly? Is it readable?
Reading: As with most of these questions, Steve McConnell's Code Complete 2 is an outstanding
resource on the subject. If you don't read anything else, read that.
- When do you use an abstract class and when do you use an interface?
I'd use an abstract class when I want to provide some implementation for reuse, but where some
also remains to be specified by the inheriting class. An interface is useful for multiple inheritance
in languages that don't allow it, as well as a decoupling device - allowing you to depend on
interfaces that don't change as often as implementations might.
Reading: Books on OO design are useful, especially those targeting static languages like Java.
- Apart from the IDE, which other favorite tools do you use that you think are essential to you?
Continuous integration tools, testing frameworks, (some people might include dependency injection
frameworks), scripting languages, the command line, source control, ... What else would you include?
Reading: McConnell's aforementioned book, The Pragmatic Programmer,
Practices of an Agile Developer,
tons of blogs that talk about the tools they use to make themselves more productive, and (although
I've only seen the presentation and not read the book), Neal Ford's The Productive Programmer
probably contains some useful items.
- How do you make sure that your code is both safe and fast?
The question seems to imply these goals are normally at odds. I haven't felt that way. I'd program for
security first, and then if it's slow, I'd try to identify the bottleneck and then find a way to improve
its time complexity. If the algorithm is already at its lower bound for time complexity, I'd move on to
micro improvements, like moving variable creation and function calls outside of loops.
- When do you use polymorphism and when do you use delegates?
I don't have any hard and fast rules. I rarely need to use polymorphism since I
primarily program in dynamic languages that make it unnecessary. (I guess it's still polymorphism, but you're not
doing anything special to achieve it.) When I have been in static languages, I'll implement
the methods that accept different types as needed to make client code more friendly to work in. If we're
actually building an API for public consumption, then obviously we have to move from "as needed" to
a more aggressive schedule.
I'm at a loss for a better answer to this question, because (surprisingly to me) I've not thought about it before now.
- When would you use a class with static members and when would you use a Singleton class?
I don't know how to answer this except for "when the situation calls for it." I'd normally opt for
the class with static members when it makes sense to do it. As far as a proper Singleton, I don't know
that I've ever written one that enforces that property. More often, if I need just one, I only create one.

- Can you name examples of anticipating changing requirements in your code?
I write unit tests, so that helps with changing requirements. How? It helps keep the design very modular to
allow for extension and easy changes, and the tests themselves provide assurance I haven't broken anything
when I do need to make a change.
I don't generally go leaving hooks and pre-implementing code that I think will be needed. YAGNI
helps guide me in that regard.
- Can you describe the process you use for writing a piece of code, from requirements to delivery?
Requirement -> unit test -> code -> run tests -> commit -> run tests -> deploy.
I think that explains it all, and explaining each step could be a blog post or more of its own.
My basic advice on how to prepare for this section of questions is: Read and internalize
Code Complete 2.
I should probably read it again, in fact.
What advice would you give?
Posted by Sam on Mar 10, 2009 at 12:00 AM UTC - 5 hrs
This is the fifth in a
series of answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
More...
This week's answers are on a topic I've been wanting to explore more in depth here lately: algorithms (though it doesn't go into as much detail). I'll
wait until the end to give reference information because all of this post relies on experience, but there
are two sources where I'd start learning the information for every question. Trying to keep the post
DRY and all.
- How do you find out if a number is a power of 2? And how do you know if it is an odd number?
To find out if a number is a power of two, you can divide by two until the number is 1 or odd. If the number is odd
at any point before you reach one, the number is not a power of two. To find out if a number is odd, I'd normally
take number mod 2 and see if the result is 1 or not (1 would mean the number is odd). If performance
is a concern and the compiler or runtime doesn't optimize for mod 2, you could use a bit mask that
checks if the smallest bit is set or not. If so, the number is odd. If not, the number is even.

Here's an example with the bit mask:
def even? n
n == n & 0b11111111_11111111_11111111_11111110
end
n = 512
while even?(n) && n > 1 do
n = n >> 1
end
puts n==1
Note you'll need a large enough bit mask to cover the size of the number in bits.
- How do you find the middle item in a linked list?
If it's important to be able to find the middle element, I'd keep a pointer to it. If it's implemented using an
array and it's important, we can store the array length and divide by two. If it's implemented using pointers to
elements, we can iterate over the list while counting its length, then iterate from the beginning until we get
halfway there. We could also take the size of the structure in memory and divide by two, going straight to that
element by adding 1/2 the size to the pointer, but that'd be a mighty WTF to most programmers when trying
to understand it.
- How would you change the format of all the phone numbers in 10,000 static html web pages?
Not by hand if I could avoid it. I'd write a regex that matches any of the known formats in the set of pages
and use a language with a function that replaces based on a regular expression find.
- Can you name an example of a recursive solution that you created?
I was creating a pattern enumeration algorithm in an effort to statistically identify potentially important
subsequences in a given genome. The more immediate goal was to identify Rho sites
in a set of bacterial genomes. Since we wanted to identify any potential pattern, the form needed to be general,
so a variable depth was required and we used recursion to achieve this. (This is a job interview, so I tried to
think of the most impressive sounding example from the last year I could think of.)

- Which is faster: finding an item in a hashtable or in a sorted list?
Item retrieval is basically O(1) in a hash table, while O(log n) in a sorted list, so the hash table is faster on
average.
- What is the last thing you learned about algorithms from a book, magazine or web site?
I guess it depends on what you'd consider learning. For instance, I recently looked up
merge sort to use as reference in writing a sorting
algorithm for a custom data structure, but I wouldn't say I "learned" it there. If you take "learning" as
being introduced to, it was in a course at school or via a book.
- How would you write a function to reverse a string? And can you do that without a temporary string?
In most instances I'd be working with a language that already implements a reverse method for strings.
If not working in such a language, and I'm using a temporary string, the problem boils down to iterating backwards
over the given string, and assigning tempstring[realstring_length - i] = realstring[i]. If we restrict
the usage of a temporary string, then we can just use a variable to store the current character for swapping:
for(i=0; i<len; i++) {
lowerchar = realstring[i];
realstring[i] = realstring[len-i-1]; // -1 for 0 based arrays
realstring[len-1] = lowerchar;
}
- What type of language do you prefer for writing complex algorithms?
I prefer very super extremely high level languages (to distinguish from VHLL)
that tend to be dynamic. The reason is that, in using them, I don't have to worry about low level details
that might otherwise get in the way of understanding the algorithm. After that, I'll normally have to implement
the same algorithm in a lower level language and take care of the details I could otherwise ignore, because
normally performance is going to matter when developing that complex algorithm.
- In an array with integers between 1 and 1,000,000 one value is in the array twice. How do you determine which one?
I'd insert each value as a key in a hash and when the key already exists, I know we've hit the duplicate. This
gives us O(n) time complexity, which I'm sure could be proven to be the lower bound.
- Do you know about the Traveling Salesman Problem?
Yes, it's famous. The problem asks us to find the shortest path that visits every node in a graph.
I promised you reading material, so here it is:
- The Art of Computer Programming series by Donald Knuth
- Wikipedia's list of algorithms is another good place to start.
What advice would you give?
Posted by Sam on Mar 17, 2009 at 12:00 AM UTC - 5 hrs
This is the sixth in a
series of answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
More...
This week's answers about data structures are complementary (indeed very intertwined with) last week's questions about algorithms.
Also like last week, I'll
wait until the end to give reference information because all of this post relies on experience, but there
are two sources where I'd start learning the information for every question.
- How would you implement the structure of the London underground in a computer's memory?
Without having travelled to London or on its subway system, I'd guess a graph would be the right
data structure. The set of vertices would represent the stations, and the edges connecting them would
be the tracks.
Not safe for work (language):
I don't know the proper in-memory representation of tramps.
- How would you store the value of a color in a database, as efficiently as possible?
Efficiently for retrieval speed, storage speed, size? I'm guessing size. After asking why such efficiency is
needed, and assuming we're talking about a range of up to 166 colors (FFFFFF), I'd just store it as the smallest
integer type where it would fit.
- What is the difference between a queue and a stack?
A queue is typically FIFO (priority queues don't quite follow that)
while a stack is LIFO. Elements get inserted at one end of a
queue and retrieved from the other, while the insertion and removal operations for a stack are done
at the same end.
- What is the difference between storing data on the heap vs. on the stack?
The stack is smaller, but quicker for creating variables, while the heap is limited in size only by how much
memory can be allocated. Stack would include most compile time variables, while heap would include anything
created with malloc or new. (This is for C/C++, and not strictly the case.)
- How would you store a vector in N dimensions in a datatable?
I need a little direction for this question, as I know not what it means. I encourage my readers, who have
on most occasions proven themselves more adept than me, to come through again.
- What type of language do you prefer for writing complex data structures?
I can't imagine using anything higher level than C or C++. Anything more advanced has most anything already
built and not very easily molded. Or perhaps I just wouldn't think of it as complex.
- What is the number 21 in binary format? And in hex?
10101 in binary and 15 in hex, and no I didn't cheat and use a calculator. It works just like decimal.
Take the following digits of an arbitrary number in base B:
UVWXYZ
The number in decimal is U*B5 + V*B4 + W*B3 + X*B2 + Y*B1 + Z*B0
As more digits are added, you just increase the power by which it is raised. Also note that any number raised
to the zeroth power is 1, so the Z element is just itself, and the ones digit.
- What is the last thing you learned about data structures from a book, magazine or web site?
As with my answer to this question with regard to algorithms, I'm certain I've used to web for reference here,
but I'd guess my introduction and original knowledge acquisition came from a book.
However, I would add journal article to the list of answers, because in both cases that would have been my
answer, even though I read them via the web.
- How would you store the results of a soccer/football competition (with teams and scores) in an XML document?
<fixtures>
<fixture>
<team name="Chelsea FC">
<score>0</score>
</team>
<team name="Fulham FC">
<score>1</score>
<!-- any other stats? -->
</team>
</fixture>
</fixtures>
That might be reasonable.
- Can you name some different text file formats for storing unicode characters?
I have to be honest here and say I don't know what you're talking about. I can't think of a file format
that wouldn't take it.
Again the reading material is similar to last week:
- The Art of Computer Programming series by Donald Knuth
- Wikipedia's list of data structures is another good place to start.
- Perhaps a book or resource on data modeling, since there were XML and DB questions.
What advice would you give?
Posted by Sam on Apr 14, 2009 at 12:00 AM UTC - 5 hrs
This is the eight in a
series of answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
More...
- What kind of tools are important to you for monitoring a product during maintenance?
I rely on logs and profiling tools on occasion. I'm
really interested to hear from the rest of you about this though.
- What is important when updating a product that is in production and is being used?
I'd say it's important not to interrupt service. Surely there must be something else you're
getting at?
- How do you find an error in a large file with code that you cannot step through?
cout, puts, printf, System.Out.print, Console.Out.WriteLine, and ## have all
been useful for me at one time or another.
A good strategy here is to isolate the code that's causing the error by removing code and faking results.
By doing that, you can slowly add code back in until the error reappears. Rewrite that part.
- How can you make sure that changes in code will not affect any other parts of the product?
Regression tests!
- How do you create technical documentation for your products?
Ideally I'd have comments that can be harvested by tools like RDoc or JavaDoc, but times are often
less than ideal.

- What measures have you taken to make your software products more easily maintainable?
See my answers to the questions about technical design.
Also, having unit tests helps handily.
- How can you debug a system in a production environment, while it is being used?
You can read logs if important events are being logged.
Profiling tools exist for this purpose, but I don't have experience with any outside of those for
use with databases.
- Do you know what load balancing is? Can you name different types of load balancing?
One computer acts as the gatekeeper for an array of computers and directs requests to the others
to "balance the load" of the entire system.
I'm not familiar with different types, but just guessing I'd assume they have round-robin and need-based
load balancing. I'd also presume any other scheduling algorithmic scheme could be applied in load
balancing.
I'm more interested to know why this is on the maintenance list of questions. Is it because you've deployed
your application and now you need to scale it with hardware?
- Can you name reasons why maintenance of software is the biggest/most expensive part of an application's life cycle?
One view is that after you write the first line of code, you begin maintenance. But more in-line with the
popular view: it lasts the longest. You may take a month to build a system that will be in production over
several years. During that time, defects are found that need to be fixed, business rules may change, or
new features may be added.
Also, we suck at writing software.

- What is the difference between re-engineering and reverse engineering?
I didn't know this one. I thought and would have responded that re-engineering would be
rebuilding an application with a white box, while reverse engineering would be done through a black box.
According to Wikipedia, who is never wrong,
The reengineering of software was described by Chikofsky and Cross in their 1990 paper, as "The examination and alteration of a system to reconstitute it in a new form". Less formally, reengineering is the modification of a software system that takes place after it has been reverse engineered, generally to add new functionality, or to correct errors.
This entire process is often erroneously referred to as reverse engineering; however, it is more accurate to say that reverse engineering is the initial examination of the system, and reengineering is the subsequent modification.
How would you answer these questions about software maintenance?
Posted by Sam on Apr 25, 2009 at 12:00 AM UTC - 5 hrs
This is the ninth in a
series of answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
Browsing through the questions, I'm not confident here of my ability to answer without asking
some preliminary questions (which I have no one to answer), so please chime in if you have something to add.
More...
- Do you know what a baseline is in configuration management? How do you freeze an important moment in a project?
A baseline in configuration management is the same as a baseline anywhere else - some place which serves as
a starting point or point we can return to to compare one point in time to another.
Freezing an important moment in a project to me sounds like creating a new major or minor version - so I may make
a new tag in the version control system.
- Which items do you normally place under version control?
I can't think of anything I'd not put under version control aside from user-specific project settings
and files created while executing the software (like logs, for instance) that are always likely to cause
change conflicts between different developers.

- How can you make sure that team members know who changed what in a software project?
Give everyone separate accounts to access the VCS.
Some people like to keep a change log at the top of each file, but I think that gets ignored and becomes
useless.
- Do you know the differences between tags and branches? When do you use which?
A tag is for a static snapshot, a branch is intended for development outside the trunk.
- How would you manage changes to technical documentation, like the architecture of a product?
I'd put them in VCS along with the rest of the project. I have to say though - I'm not sure I understand what
this question is really asking.
- Which tools do you need to manage the state of all digital information in a project? Which tools do you like best?
This is another question which I'd need prodding to give a more useful answer. My favorite would be a VCS, but
what else exists? Are we talking about using Wikis and bug/issue trackers? Are we talking about using Excel to
create spreadsheets to manage burndown charts and make predictions as to project completion dates? Are we
talking about using Word to manage user documentation?
I'm unsure.
- How do you deal with changes that a customer wants in a released product?
I mainly deal in web development, so in that case we just make the change and re-deploy the web application.
In desktop applications, I've only ever released projects to customers who will be using it on so few machines
that coming up with an automatic update strategy would have been a waste of resources.
If it was the right
project, I'd have it do a call to a central server that looks for updates, and perform the updates automatically.
In that case, we just make the updates and set a flag when a customer wants a change to a released product.

- Are there differences in managing versions and releases?
As with so many things in software development, the answer depends on how you view versions and releases.
If you view a release as the deliverable to customers and a version as a concept to get you there, then
the answer is undeniably yes.
If you view versions and releases as the same things, then perhaps not so much.
Do you have multiple versions between releases? There are many questions to ask here, and I certainly don't
have all the answers. Personally, I see them as a combination of the two views I mentioned above:
the version is the version of the code that we tag at certain points in time. The release happens in
tandem, but it is the deliverable we give to clients - so they differ in the way we manage them, because
it's not simply an issue of "commit->version->release." I'd love to get there, but I'm not close yet.
- What is the difference between managing changes in text files vs. managing changes in binary files?
diff is much less useful in highlighting differences in binary files than it is in text files (at least
as far as the person running the diff is concerned). It is much harder to manage conflicting changes in binary
files as a result.
- How would you treat simultaneous development of multiple RfC's or increments and maintenance issues?
I fear I don't understand what this question is asking. RfC == Request for Comments? What does that
have to do with increments and maintenance issues? Any advice as to what you think this question means
is truly appreciated.
Reading through and answering these questions has made one thing very clear to me: I'm stuck in the middle
of the forest and I'm only seeing the trees. I don't have a strategy when it comes to configuration management
and version control. I use it, because I know I should, and it has some benefits. However, focusing
only on the tactical side means I'm not getting as much out of it as I could.
How would you answer these questions about configuration management?
Posted by Sam on May 19, 2009 at 12:00 AM UTC - 5 hrs
This is the tenth and final post in a
series of answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
More...
- How many of the three variables scope, time and cost can be fixed by the customer?
Two. (See The 'Broken Iron Triangle' for a good
discussion.)
- Who should make estimates for the effort of a project? Who is allowed to set the deadline?
The team tasked with implementing the project should make the estimates. The deadline can be set by
the customer if they forego choosing the cost or scope. There are cases where the team should set the deadline.
One of these is if they are working concurrently on many projects, the team can give the deadline to management,
with the knowledge that priorities on other projects can be rearranged if the deadline for the new project
needs to be more aggressive than the team has time to work on it.
Otherwise, I imagine management is
free to set it according to organizational priorities.
- Do you prefer minimization of the number of releases or minimization of the amount of work-in-progress?
I generally prefer to minimize the amount of work on the table, as it can be distracting to
- Which kind of diagrams do you use to track progress in a project?
I've tended to return to the burndown chart time after time. Big visible charts
has some discussion of different charts that can be used to measure various metrics of your project.
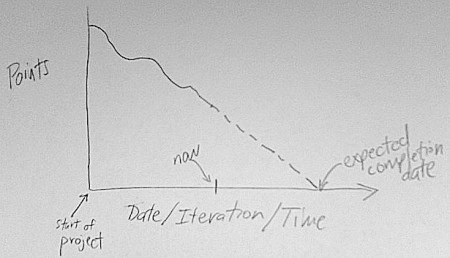
- What is the difference between an iteration and an increment?
Basically, an iteration is a unit of work and and increment is a unit of product delivered.
- Can you explain the practice of risk management? How should risks be managed?
I don't know anything about risk management formally, but I prefer to to deal with higher risk items first
when possible.
- Do you prefer a work breakdown structure or a rolling wave planning?
I have to be honest and say I don't know what you're talking about. Based on the names, my guess would be
that "work breakdown structure" analyzes what needs to be done and breaks it into chunks to be delivered
in a specific order, whereas rolling wave may be more like do one thing and then another, going with the flow.
Wikipedia shows what I had in mind about WBS,
while pmcrunch.com has info on RWP.
After reading about RWP I realized that I had already known about it - it was just buried deep in my memory.
In any case, I would think like most everyone else that I'd prefer the work breakdown structure, but it's
unrealistic in most projects (repetitive projects could use it very successfully, for instance). Therefore,
I'll take the rolling wave over WBS please.
- What do you need to be able to determine if a project is on time and within budget?
Just the burndown chart, if it's been created out of truthful data.
- Can you name some differences between DSDM,
Prince2
and Scrum?
I'm not at all familiar with Prince2, so I can't talk intelligently about it. DSDM is similar to Scrum in that
both stress active communication with and involvement of the customer, as well as iterative and incremental
development. I'm not well versed in DSDM, but from what little I've heard, it sounds a bit more prescriptive than
Scrum.
I'd suggest reading the Wikipedia articles to get a broad overview of these subjects - they are decent starters.
It would be nice if there were a book that compared and contrasted different software development
methodologies, but in the absence of such a book, I guess you have to read one for each.
- How do you agree on scope and time with the customer, when the customer wants too much?
Are they willing to pay for it? If they get too ridiculous, I'd just have to tell them that I can't do what they're asking
for and be able to pay my developers. Hopefully, there would be some convincing that worked before it came to
that point, since we don't want to risk losing customers. However, I must admit that I don't have any strategies
for this. I'd love to hear them, if you have some.
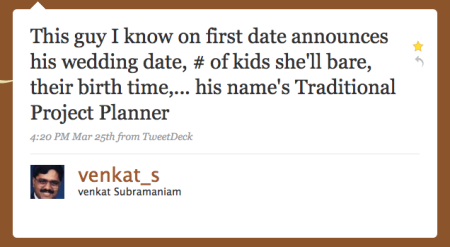
There are a couple of stories you can tell:
- about 9 women having one baby in just one month. (Fred Brooks)
- about your friend with an interesting first date philosophy (Venkat Subramaniam)
How would you answer these questions about project management?
Posted by Sam on Jun 17, 2009 at 12:00 AM UTC - 5 hrs
This is the third in a series of
answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
Last week's answers on Functional Design
had me feeling that way. Luckily, this week we come to technical design - a topic I feel quite a bit stronger on.
More...
- What do low coupling and high cohesion mean? What does the principle of encapsulation mean?
Coupling refers to how strongly or loosely components in a system are tied together. You want that to be
low. Cohesion refers to how well the individual parts of a unit of code fit together for a single purpose.
Encapsulation is about containing implementation of code so that outsiders don't need to know how it's works
on the inside. By doing so you can reduce negative effects of coupling.
Reading: Robert C. Martin's SOLID
principles of OOD, which have been linked on this blog since day 1. His book, Agile Software Development: Principles, Patterns, and Practices
is another great resource for this topic. It's short and to the point, and comes highly recommended from myself.
- How do you manage conflicts in a web application when different people are editing the same data?
Set a flag when someone starts editing data unit A. If someone else loads it, let them know it's being edited
and that it's currently in read only mode. If the race was too fast, you can also have a check on the
commit side to let them know their changes conflict with another user, present them the data, and then let
them figure out how to merge the changes. This has rarely been a problem in my experience, but it could be,
and that's how I'd deal with it if the requirement came up. (If the changes don't conflict, you could
simply keep the user unaware as well.)
My answer comes from the things you see in normal usage of shared files or just about any shared resource,
for that matter. Originally,
it comes down to race conditions, so you might
be able to extrapolate some useful information from that low-level explanation.
- Do you know about design patterns? Which design patterns have you used, and in what situations?
I know about design patterns. Most of the ones I'm familiar with, at least in the canonical book,
aren't of much daily use to me, as I tend to work in dynamic languages, where the sorts of flaws that precipitate
the patterns (as implemented in the book) just aren't factors as often as in other languages. (Yes, some of the
book is implemented in Smalltalk. I can implement them with as much superfluous junk as you desire in
any language - that doesn't make it a necessity.)
I suppose most frequently I've used the Strategy pattern.
(Perhaps the fact that I've focused so much on one in particular is a weakness in my coding style?) The situations
are when an interface should remain the same while the implementation should differ somewhat. I don't have a
concrete example on the top of my head.
If I were to start working in Java again, or building larger applications in .NET (I currently build very small
apps in that space as part of my job), I'd re-read the book. I might even scan the inner cover daily just as a
refresher.
I wouldn't say I'm strong on design patterns, but I've got reference information and know where to look
should I need to, along with the facilities to become strong should my situation call for it.
Reading: The aforementioned book, Design Patterns: Elements of Reusable Object-Oriented Software.
I hear good things about the better-selling Head First Design Patterns,
but I've not read it myself, so I can't speak to its efficacy.
- Do you know what a stateless business layer is? Where do long-running transactions fit into that picture?
I hadn't heard it as a single term until now, but knowing the individual terms lets me say that objects in
the business layer (or domain model) are transient - or that their state is not preserved in memory between
subsequent requests for the same object.
This may note bode well for long running transactions, as state presumably must be set up each time an
object is loaded, along with any process that might be required for tear-down.
For reading, this is just information as I've come across it throughout my various readings, so I don't
know what to recommend.
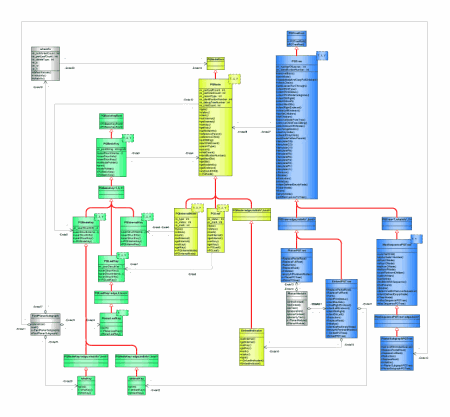
- What kinds of diagrams have you used in designing parts of an architecture, or a technical design?
UML, or some bastardization of it has always been enough.
Most likely the bastardized part where we just do a little design on paper or a whiteboard to gain a
better understanding of the intended design through some sketch-work.
I've never been a part of a team that practices BDUF, nor
have I felt the need for it in any personal projects, so I'm light on recommendations for reading.
The Wikipedia article on UML is
sufficient for my tastes, but I've know people who dove into Martin Fowler's books
and came away more knowledgeable, so that may help you.
- Can you name the different tiers and responsibilities in an N-tier architecture?
For what value of N? (I mean, we could have N=1000000 and I wouldn't know -- or if I did know, we might
be here all day.) Normally N=3, so we might be talking about presentation, logic, and data tiers. Sometimes
we might talk about Entities and others, or we might be considering (mistakenly?) MVC.
I think the responsibilities are clear by their names, but if you'd like to discuss further, I'm
certainly okay with doing so.
Reading: As often is the case, Wikipedia provides a good starting point,
though certainly it's a topic with enough depth one could read several books about it.
- Can you name different measures to guarantee correctness and robustness of data in an architecture?
I need a little direction here. It seems to me this is a product of many things, and I don't know where to start.
For instance, we could say that unit tests and integration tests can go part of the way there. We could
talk about validating user input, and that it matches some definition of "looking correct." We could
have checks coded and in place between the various systems that make up the architecture. Constraints on the
database. I could go on if I were giving myself more time to think about it.
Because of the open-endedness in this question, there are any number of references. I'd dive into
automated testing in its various forms, which when applied to the situation, should get you most of the
way there.
- Can you name any differences between object-oriented design and component-based design?
To be honest, this is the first I've heard of component-based design, so no, I can't name the differences.
My thoughts would go towards having objects to design around (as in C++) vs. not having objects to
design around (as in C).
As it happens, there may be a reason the term "component-based design" seems new to me: IEEE held the
"1st ... workshop" on it not 6 months ago. They could very well be behind the times.
Searching with Google also indicates this may be designing from the view of the outside,
as in SOA.
I think the SOLID principles I mentioned above go beyond the availability of objects-proper, so I don't expect
to be surprised here. However, I can't offer you any reading advice and without a definitive source
from the Google results, I cannot even tell if I'm in the right ballpark.
Your thoughts are especially encouraged on this topic.
- How would you model user authorization, user profiles and permissions in a database?
I wouldn't typically model the authorization piece in the DB. If I read you correctly, I'm
guessing you mean the storage of authorization information in the database, as opposed to the
act of authorizing. Under that assumption, I've modeled this situation in just about every
way I can imagine. A couple of scenarios:
a. Under a denormalized scenario, I'd keep a table of permissions and a table of users (which includes authorization
information, profile information, and a list of permissions from the users table). This isn't ideal if permissions
ever change, and especially not if you're returning a ton of users for the purpose of authorization while the
profile information is especially large. In that case you're transferring way more data than you need, and it could
result in performance problems. (The extra data transfer may only be a problem with ORM tools, as you
could always hand-write the queries to return only what you need.
On the other hand, storing of redundant data is a problem if storage space itself is an issue.)
b. Under a completely normalized scenario, we'd have a table of permissions, a table relating users
to permissions, and a table for users. For the sake of cohesion (and potentially optimizing data transfer)
we might separate the users table into one for authentication and another for profile, while keeping the
relationship with permissions based on user_auth.
c. Some variation in between the two extremes.
For reading? For me it's based on experience, and perhaps a couple of database courses in college. I guess
just about any book on database design would do. I wouldn't bother trying to understand the formal
academic descriptions of database normalization,
but if you want to, you can only be better for it (as long as you can recognize the tradeoffs due to extra
joins!) Reader suggestions are highly welcome, as always.
- How would you model the animal kingdom (with species and their behavior) as a class system?
This one might deserve a blog post all on its own. It depends: If I'm working in a language with
multiple inheritance, I'd use a combination of class hierarchy that follows the animal kingdom along
with mixins (which are also inheritance, but with less of a hierarchical attitude) for behavior shared
between and among the hierarchy levels. Without multiple inheritance, I'd have to resort to
interfaces where available, and composition for actual code reuse where it made sense.
The short answer though, is that I probably wouldn't implement it as a class system. If I really was working
with taxonomy and biological classification,
I don't think I'd model the real world with objects. I'd need to look into the subject quite a bit further
to tell you how I would do it, but suffice to say I don't think it'd be using objects to match
it one-for-one, or even something resembling one-to-one.
Reading: I wouldn't know where to begin. The SOLID principles will guide you, but I wouldn't think that's all
there is to it.

What do you think? Where would your answers differ?
|
Me

|
